Can the covariance matrix have imaginary eigenvectors?
Can the covariance matrix be non-symmetric? Turns out yes, if we consider random variables that take values in a non-commutative ring. How can we construct such a random variable and what is the significance of it?
math
statistics
linear algebra
English
Published
May 27, 2026
Abstract
At work I told a friend of mine that the covariance matrix can have imaginary eigenvalues. This supposedly would encode rotation of some sort in empirically collected data. However, I was wrong: The covariance matrix cannot have imaginary eigenvalues, because it is a real symmetric matrix (and all eigenvalues of a real symmetric matrix are real). Or was I?
The covariance matrix
The covariance matrix is commonly defined as:
\[
\begin{aligned}
&\text{cov}(X,Y) := \mathbb{E}[(X - \mathbb{E}(X))(Y - \mathbb{E}(Y))^T] \\
&\text{where} \\
&\quad\quad X, Y : (\Omega, \mathcal{F}, P) \xrightarrow{\text{measurable}} (\mathbb{R}^n, \mathcal{B}(\mathbb{R}^n)) \\
&\quad\quad (\Omega, \mathcal{F}, P) \text{ is a probability space} \\
&\quad\quad \mathcal{B}(\mathbb{R}^n) \text{ is the Borel sigma-algebra on } \mathbb{R}^n
\end{aligned}
\]
If we are given only one random variable \(X\), we can define the covariance matrix of \(X\) as \(\text{cov}(X) := \text{cov}(X,X)\), which is also called the auto-covariance matrix of \(X\). Clearly this auto-covariance matrix is real and symmetric:
As a real symmetric matrix, it cannot have imaginary eigenvalues: Remember that an eigenvalue \(\lambda\) of a matrix \(A\) is defined by the equation:
\[
Av = \lambda v
\]
and it therefore can be obtained by solving the characteristic polynomial:
\[
\chi_A(\lambda) = \det(A - \lambda I) = 0.
\]
Remember that the determinant of a matrix can be thought of as measuring the “volume” of the parallelepiped spanned by the columns of the matrix. Stating that \(\chi_A\) only has real roots geometrically means that the “volume” of the parallelepiped spanned by the columns of \(A - \lambda I\) can only be zero for real values of \(\lambda\).
Warning
TODO: explain fully why the eigenvalues of a real symmetric matrix are real.
Breaking the symmetry
How would we be able to have a non-symmetric auto-covariance matrix? We would need to have \[
\exists i, j \in \{1, \ldots, n\} : \mathbb{E}[(X_i - \mathbb{E}(X_i))(X_j - \mathbb{E}(X_j))] \neq \mathbb{E}[(X_j - \mathbb{E}(X_j))(X_i - \mathbb{E}(X_i))].
\]
Here, let us first establish without loss of generality that all \(X_i\) are centered, i.e. \(\mathbb{E}(X_i) = 0\) for all \(i\). Then the above condition can be rewritten as:
The multiplication of real random variables is commutative, as it is lifted from the multiplication of real numbers. We will have to consider a non-commutative multiplication to break the symmetry of the auto-covariance matrix, obviously! We can now move over to another ring. In this example, we will consider \(\mathbb{H}\), the ring of quaternions, which is a non-commutative extension of the complex numbers. The quaternions are defined as:
\[
\mathbb{H} := \{a + bi + cj + dk : a, b, c, d \in \mathbb{R}, i^2 = j^2 = k^2 = ijk = -1\}
\]
Alternatively, we could mod out the following ideal from the polynomial ring \(\mathbb{R}[i,j,k]\):
\[
\mathbb{H} \cong_\text{Ring} \mathbb{R}[i,j,k] / (i^2 + 1, j^2 + 1, k^2 + 1, ij - k, jk - i, ki - j).
\]
We call the elements \(bi + cj + dk\)imaginary, in analogy to the complex numbers. The elements \(a\) are called real.
We can now find a non-symmetric auto-covariance matrix by considering the following random variable, by using \(i j = k\) and \(j i = -k\):
To find out the geometric significance of the constructed imaginary eigenvalues, we first need to understand in what way the eigenvalues and eigenvectors of the auto-covariance matrix encode geometric properties of the data.
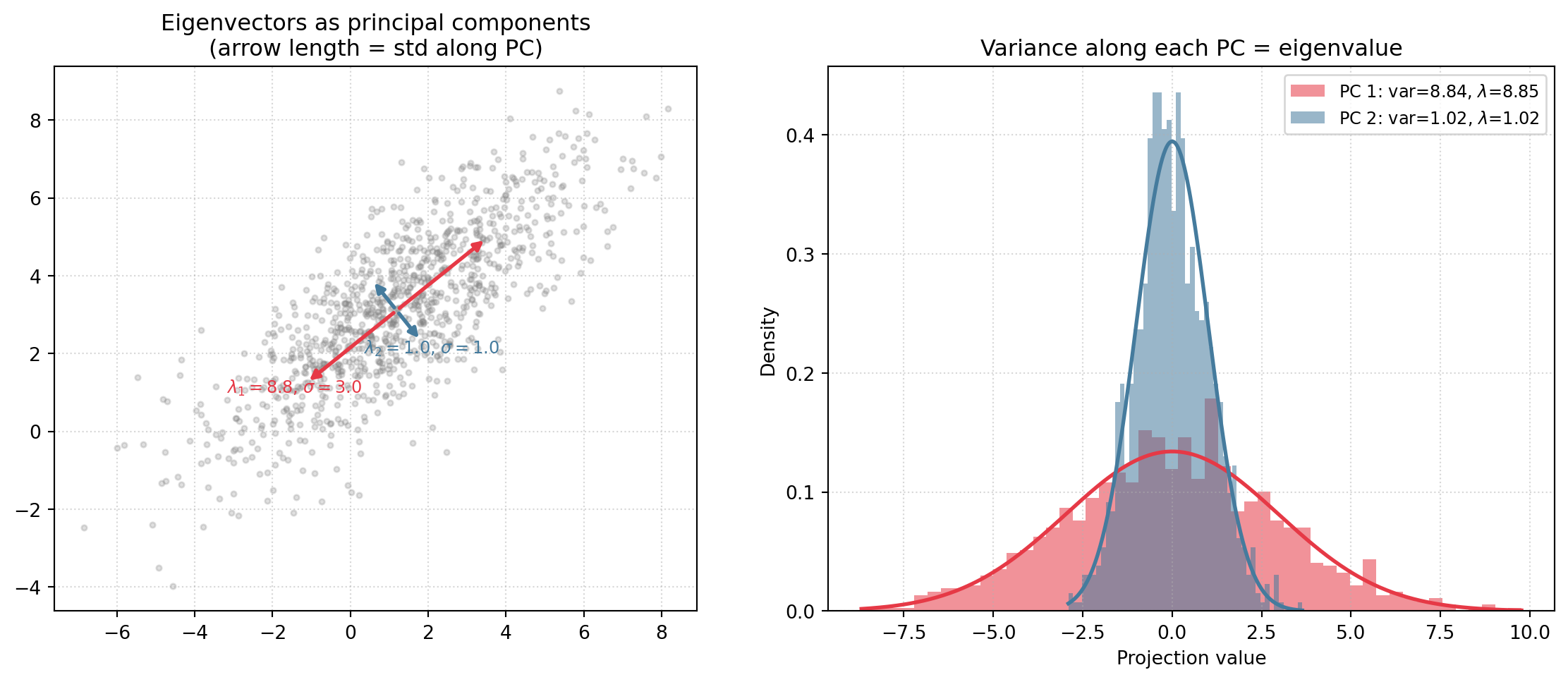
Principal components as eigenvectors
When working with collected samples \(x_1, \ldots, x_N\) of a random variable \(X\), we often work with the sample covariance matrix\(\Sigma_X\), which is defined using the data matrix\(D_X\):
It is well known (see corollary 5.2 https://www.cs.columbia.edu/~djhsu/AML/lectures/notes-pca.pdf), that the eigenvectors of \(\Sigma_X\) are the principal components of the data, and that the eigenvalues of \(\Sigma_X\) are the variances of the data along those principal components. The principal components are obtained by rotating the data in such a way that the variance along each principal component is maximized:
Remember that the standard inner product on \(\mathbb{R}^n\) is defined as \(\langle x, y \rangle = x^T y\), and we have the well known cosine similarity formula: \[
\cos(\theta)\|x\| \|y\| = \langle x, y \rangle = x^T y = \sum_{i=1}^n x_i y_i
\] If \(x_{\cdot ,1}\) and \(x_{\cdot, 2}\) in the above example were normed, then the covariance matrix would encode the cosine similarity between the rows of the data matrix, or equivalently the sampled \(x_i\).
The diagonals would clearly just be the lengths (which we assumed to be normed). Dropping our norm assumption, we would therefore be able to obtain the cosine similarity of the data points, by considering the off-diagonal entries of the covariance matrix and dividing them by the square root of the product of the diagonal entries.
Similarly, we can detect the principal components of 3d point clouds. This however crucially only detects the spread of the data along the principal components. If our data has a shape different from a Gaussian blob, PCA will fall short.
Some standard solutions to this problem are Nonlinear PCA, for example by using kernel methods.
None of these approaches take into account the orientation of our data. It does not matter in which order the data points \(x_i\) are collected and assembled into the data matrix \(D_X\): Assume we permute the data points, resulting in a permuted data matrix \(P D_X\), where \(P\) is a permutation matrix. Then we have \[
\Sigma_{P X} = \frac{1}{N} (P D_X)^T (P D_X) = \frac{1}{N} D_X^T P^T P D_X = \frac{1}{N} D_X^T D_X = \Sigma_X.
\]
and so we can take the sampled data points \(x_i, \dots, x_N \in \mathbb{R}^3\) from the previous examples and embed them into \(\mathbb{H}^N\). We can now compute the auto-covariance matrix of the result as in the previous chapter and we can compute the eigenvalues of the resulting non-symmetric auto-covariance matrix.
Code
import quaterniondef iota(x, y, z):return x * quaternion.x + y * quaternion.y + z * quaternion.zX1_quat = np.array([iota(*p) for p in X1])cov_quat = X1_quat[:, np.newaxis] * X1_quat[np.newaxis, :]
Warning
TODO: here I am stuck on how I should best compute the eigenvalues of this matrix of quaternions using NumPy and on what the consequences of the resulting eigenvalues are for the geometry of the data.